
- Istio an introduction
- Getting started with Istio
- Istio in Practice – Ingress Gateway
- Istio in Practice – Routing with VirtualService
- Istio out of the box: Kiali, Grafana & Jaeger
- A/B Testing – DestinationRules in Practice
- Shadowing – VirtualServices in Practice
- Canary Deployments with Istio
- Timeouts, Retries and CircuitBreakers with Istio
- Authentication in Istio
- Authorization in Istio
- Istio series Summary
It’s not always that the code is buggy. In the list of “The 8 fallacies of distributed computing” the first fallacy is that “The network is reliable”. The network is definitely NOT reliable, and that is why we need Timeouts and Retries.
For demonstration purposes, we will continue to use the buggy version of sa-logic, where the random failures simulate the unreliability of the network.
The buggy service has a one-third chance of taking too long to respond, one-third chance of ending in an Internal Server Error and the rest complete successfully.
To alleviate these issues and improve the user experience we could:
- Timeout if the service takes longer than 8 seconds and
- Retry on failed requests.
This is achieved with the following resource definition:
- The request has a timeout of 8 seconds.
- We attempt 3 times
- An attempt is marked as failed if it takes longer than 3 seconds.
This is an optimization; the user won’t be waiting for more than 8 seconds and we retry three times in case of failures, increasing the chance of resulting in a successful response.
Apply the updated configuration with the command below:
$ kubectl apply -f resource-manifests/istio/retries/sa-logic-retries-timeouts-vs.yaml virtualservice.networking.istio.io/sa-logic configured
And check out the Grafana graphs to view the improvement in success rate, as shown in figure 1.
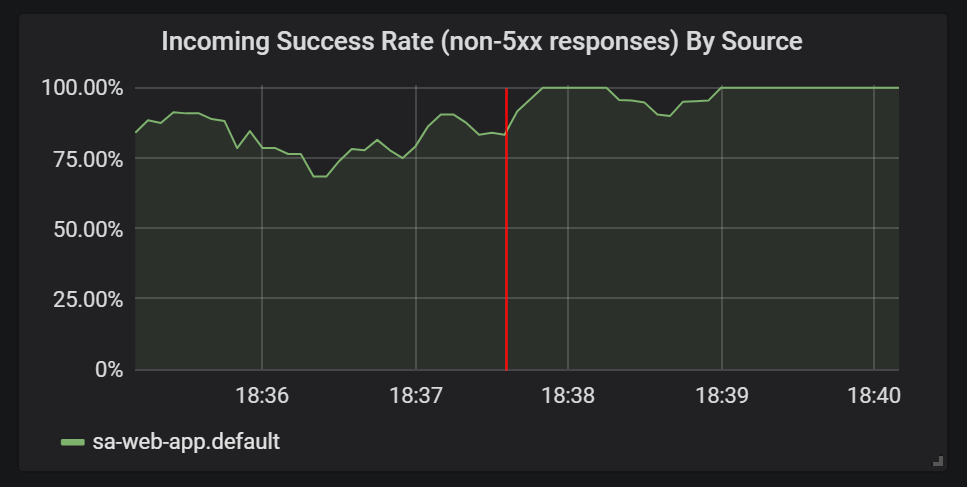
Before moving into the next section delete sa-logic-buggy and the VirtualService by executing the command below:
$ kubectl delete deployment sa-logic-buggy deployment.extensions "sa-logic-buggy" deleted $ kubectl delete virtualservice sa-logic virtualservice.networking.istio.io "sa-logic" deleted
Circuit Breaker and Bulkhead patterns
Two important patterns in Microservice Architectures that enable self-healing of the services.
The Circuit Breaker is used to stop requests going to an instance of a service deemed as unhealthy and enable it to recover, and in the meantime client’s requests are forwarded to the healthy instances of that service (increasing success rate).
The Bulkhead pattern isolates failures from taking the whole system down, to take an example, Service B is in a corrupt state and another service (a client of Service B) makes requests to Service B this will result that the client will uses up its own thread pool and won’t be able to serve other requests (even if those are not related to Service B).
I will skip implementations of these patterns because I’m way too excited to showcase Authentication and Authorization, though for implementations of those patterns you can check the official docs.
If you enjoyed the article, please share and comment below!